It has been reported that up to 80% of IoT data projects fail (the project was not completed or the company gained nothing from its implementation). If we look at the highlighted reasons for failures, we find mostly data-related topics, hazy descriptions of problems with Machine Learning methods without going into details, vaguely defined goals, and many other reasons.
In this note, I would like to focus on choosing an algorithm for IoT data analysis purposes. Before working with IoT data, it's a good idea to determine earlier which analytical solution should be implemented: based on supervised or unsupervised methods.
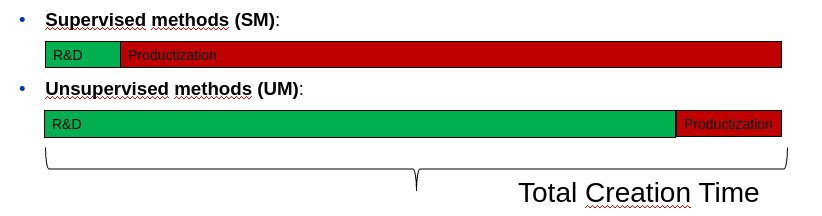
Usually creating a good unsupervised algorithm is a difficult task, more difficult than a supervised algorithm. However, building the model itself is only part of the project. The other part is its application in the production process. So I propose to look at the whole thing: the creation of an analytical method and its productization.
Solution 1 - Supervised Model (SM):
- analytical model (R&D): this is a Data Scientist (DS) standard job:
- selection of features (data and feature engineering),
- model creation,
- precise validation procedure with KPIs.
- Productization: we have to include a Data Engineer here also. Tasks to do:
- data & feature engineering, preparation of computing environment,
- framework for SM automatization including:
- monitoring of the data shifts (features + target),
- data selection for creating new models,
- data labeling,
- parameter hypertuning,
- model retraining,
- selection of the best model(s).
Solution 2 - Unsupervised Model (UM):
- R&D: DS job:
- selection of features (data and feature engineering),
- model creation,
- precise validation procedure with KPIs.
- Productization: it obeys DE + DS tasks. Main tasks to do:
- data & feature engineering, preparation of computing environment.
Comparison of both solutions:
As you can see, creating a well-functioning production cycle for the SM is a very difficult task. In my opinion more difficult than creating a proper supervised model and much more time consuming.
On the other hand, for solution 2 based on the UM, putting the solution into production is very simple. The opposite picture we have for building analytical models.
Given the above considerations, the summary statement might look like this image:
I hope you find my findings helpful. Thanks for reading !