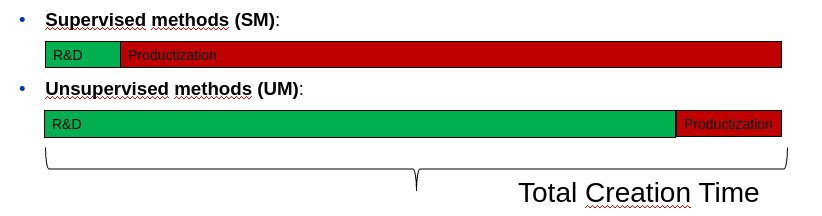
Many natural language processing (NLP) projects are based on the task of semantic text clustering. In short, we have a set of statements (texts, phrases, or sentences), and our goal is to group them semantically. Nowadays, this is quite a classical problem with a rich literature on clustering methods.
In spite of the simple formulation of the task, there are many problems during its realization. To make things more difficult, let's assume
we are dealing with unlabeled data, which means we must rely on unsupervised techniques.
The first problem:
as we know, we can find many categories according to which we can try to group the given set of texts.
In order to do this task well, we need to know the business case better. In other words, we need to know the question we want to answer using clustering.
This problem is not the purpose of this note, so we will skip it.
The second problem:
suppose we have successfully performed text clustering. And the question arises:
how do we know that all clusters contain the correct texts ?
Answering this question is the purpose of my note .
Let us assume that a given method has generated $N$ groups/clusters , each of which contains a set of similar texts .
It is known that every cluster of similar texts is more or less homogeneous. There are clusters that are completely wrong in the sense of similarity of texts.
So to answer our original question
How do we know that all clusters contain correct texts ?
is to find those clusters that contain erroneous texts.
How to find the worst clusters ?
In this note, I would like to propose the following method for determining the worst clusters:
- checking intra-cluster similarity by computing the Shanon entropy of the set of texts belonging to a given cluster.
- using dynamically determined threshold entropy to select the worst clusters (based on the method presented in my blog
https://dataanalyticsforall.blogspot.com/2021/05/semantic-search-too-many-or-too-few.html).
As data to illustrate our task I use data known as reuters-21578 (https://paperswithcode.com/dataset/reuters-21578).
Since the clustering stage is not our goal, this part of the work was done using the fast clustering method based on Agglomerative Clustering
(
https://www.sbert.net/examples/applications/clustering/README.html#fast-clustering,
code:
https://github.com/UKPLab/sentence-transformers/blob/master/examples/applications/clustering/fast_clustering.py).
Each set of texts is characterized by a different degree of mutual homogeneity.
The general idea of the method is to calculate the Shanon entropy for each identified text cluster, and then using the elbow rule to determine the homogeneity threshold (maximum entropy value) below which the clusters satisfy the homogeneity condition (are accepted). All clusters with entropy above the threshold should be discarded, used to find a better clustering algorithm or reanalyzed.
In any clustering method, we will get multiple single element clusters.
Since in our method we check for homogeneity between sentences in a cluster, therefore I calculate entropy only for multi-element clusters.
The only parameters that needs to be introduced in the proposed method are:
- the 'approximation_order' which defines a number of of consecutive characters (known as ngrams) from which we create the probability distribution used later to calculate the Shanon entropy.
- The sensitivity parameter S (to adjust the aggressiveness in kneed detection [
kneed]) used in the Python kneed library.
The complete code is available at
https://github.com/Lobodzinski/Semantic_text_clustering__testing_homogeneity_of_text_clusters_using_Shannon-entropy.
To illustrate the method I show two pictures with the final results for two values of the parameter used to determine the Shannon entropy (approximation_order: 2 and 3)
All the values of the Shannon entropy approximations are ordered from smallest to largest (y-axis). The kneed library, given a parameter S (in this case S = 1), determines the best inflection point and this entropy value defines our maximum entropy value for the accepted sentence clusters. For a given approximation_order parameter (=2), we obtain 14 clusters which are inappropriately homogeneous.
Questionable clusters are:
Cluster 13, #10 Elements
Cluster 23, #8 Elements
Cluster 26, #8 Elements
Cluster 28, #8 Elements
Cluster 49, #6 Elements
Cluster 56, #6 Elements
Cluster 59, #5 Elements
Cluster 62, #5 Elements
Cluster 127, #4 Elements
Cluster 137, #3 Elements
Cluster 145, #3 Elements
Cluster 152, #3 Elements
Cluster 247, #3 Elements
Cluster 275, #3 Elements
For comparison, the next picture is calculated for approximation_order=3.
In this case, we get 15 incorrect clusters:
Rejected clusters:
Cluster 0, #396 Elements
Cluster 13, #10 Elements
Cluster 23, #8 Elements
Cluster 26, #8 Elements
Cluster 28, #8 Elements
Cluster 56, #6 Elements
Cluster 59, #5 Elements
Cluster 62, #5 Elements
Cluster 109, #4 Elements
Cluster 127, #4 Elements
Cluster 137, #3 Elements
Cluster 145, #3 Elements
Cluster 152, #3 Elements
Cluster 179, #3 Elements
Cluster 275, #3 Elements
Comparing the list of unacceptable clusters may give more information about the occurring heterogeneities in our text set.
I encourage you to test the method for yourself. In my case it turned out to be very useful.
The code:
https://github.com/Lobodzinski/Semantic_text_clustering__another_way_to_study_cluster_homogeneity.
The outstanding advantage of the method is that it works fully autonomously without the need for human intervention.
Thanks for reading, please feel free to comment and ask questions if anything is unclear.